Welcome to my tutorial for text analysis! Why text analysis?
Digital data is everywhere! As a student, you probably interact with this digital data frequently, reading long PDFs and comparing numerous works. For written work that is digitally transcribed, text analysis is a valuable tool for students.
Text analysis includes a wide variety of techniques that can take a large amount of text data and extract interesting and important findings. Text analysis tools reveal patterns that would be difficult to do manually, importantly, with your guidance. The choices you make with your data matter, and so do the tools you use.
Voyant Text Analysis! What is Voyant? Why Use It?
Voyant is an accessible text analysis tool! A website-based resource for text reading and analysis, all you need is the link to the website, or to search for the website, and then you’ll be able to enter your own digital data to be analyzed.
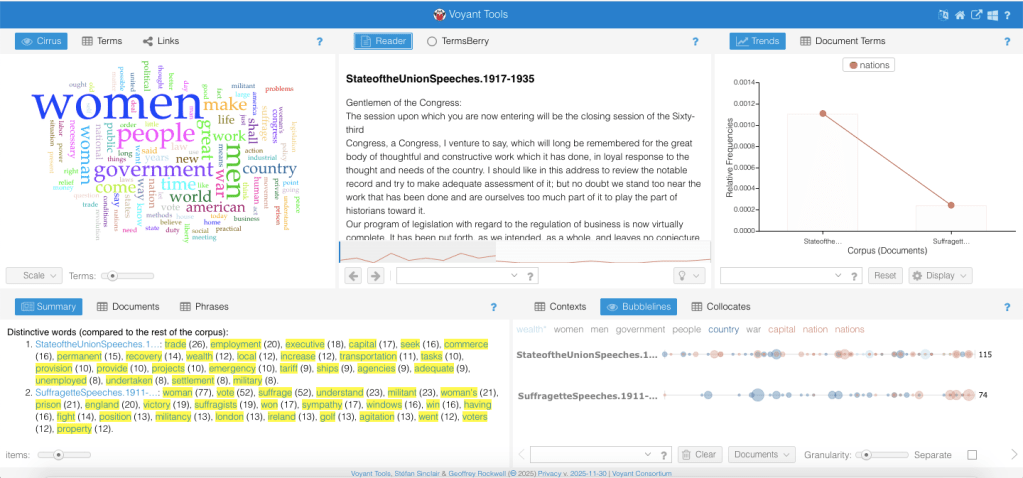
Voyant reads your data or digital text, which is also known as your corpus, and allows you to interact with the data with a number of analytic tools, which are explored in detail in the demo. My favorite aspects of this tool include the easy access the website has, which I can easily navigate on an ancient MacBook and on a new Windows laptop. It works for many docs, a few docs, one long doc, etc! It is flexible and has lots of support for further questions beyond the guide below.
This guide aims to introduce you to the resource, which is Voyant, to show you how to use some of the key concepts and tools provided by the resource, and guide your critical use of the tool depending on your data.
What’s in this guide?
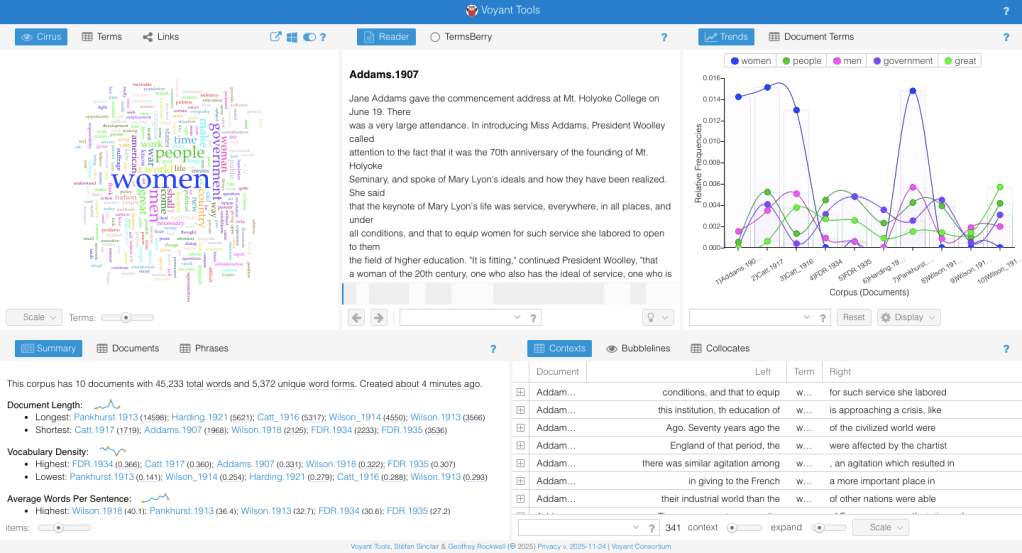
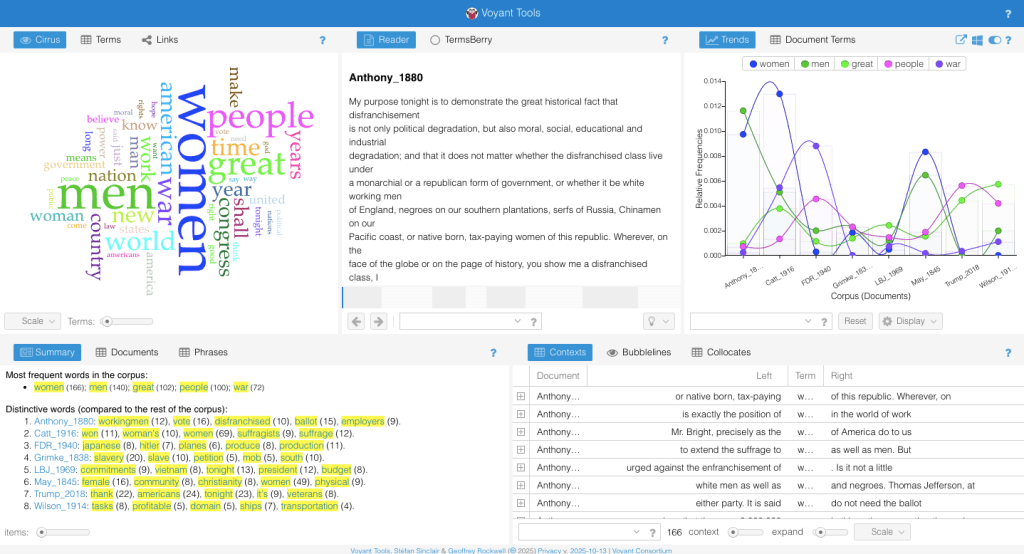
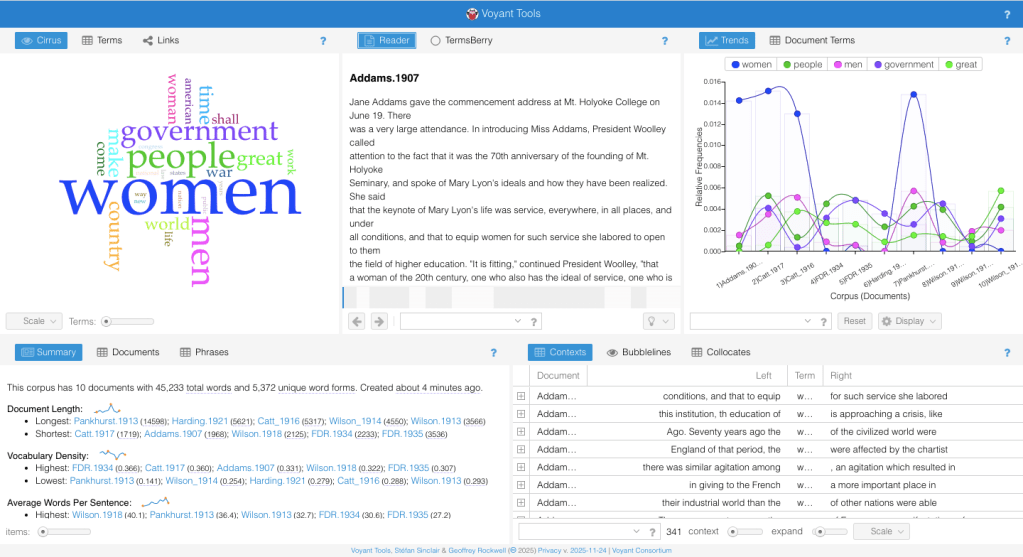
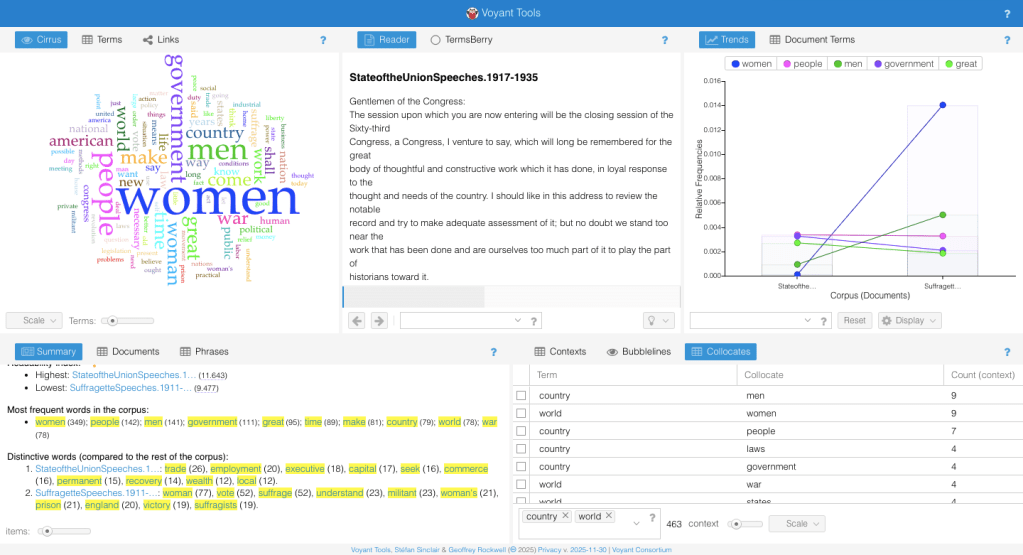
This page consists of a bunch of blog posts that take you through the step-by-step process I took with Voyant. Substeps explain specific tools and ways to engage with the tool, so you can use Voyant with confidence! I have my process of comparing five State of the Union Speeches from 1917-1935 and five Suffragette Speeches from 1911-1917. You can follow along with this demo on your own device by downloading the data I am using here in the “My data” page in the above navigation on the top right. In this demo, I wanted to compare the gendered language within these texts and learn more about the texts and their themes. This demo will take you through some of the missteps I took, so you’ll know what to do if you run into them too! Scroll down to the first blog post below to begin the demo!